Azure Pipelines


Azure Pipelines is a cloud-based continuous integration and continuous delivery (CI/CD) service offered by Microsoft as part of their Azure DevOps suite of services. It allows you to build, test, and deploy your applications and infrastructure code automatically and continuously.
Azure Pipelines supports a variety of programming languages and platforms, including .NET, Java, Python, Node.js, and many others. It also integrates with popular development tools, such as Visual Studio, Visual Studio Code, Jenkins, and GitHub, making it easy to incorporate into your existing development workflows.
With Azure Pipelines, you can create and manage build and release pipelines, and set up continuous integration(CI)and continuous delivery(CD) workflows to continuously test, build and deploy the code. It also provides a range of features and services for managing and scaling your pipelines, including agent pools, variable groups, and deployment groups.
Overall, Azure Pipelines is a powerful tool for managing the entire software delivery lifecycle, helping you to streamline your development processes and deliver high-quality software faster and more efficiently.
In Azure DevOps, we can create pipelines in two ways.
YAML pipeline Editor.
Classic Editor.
Here is the Basic Format of the YAML pipeline.
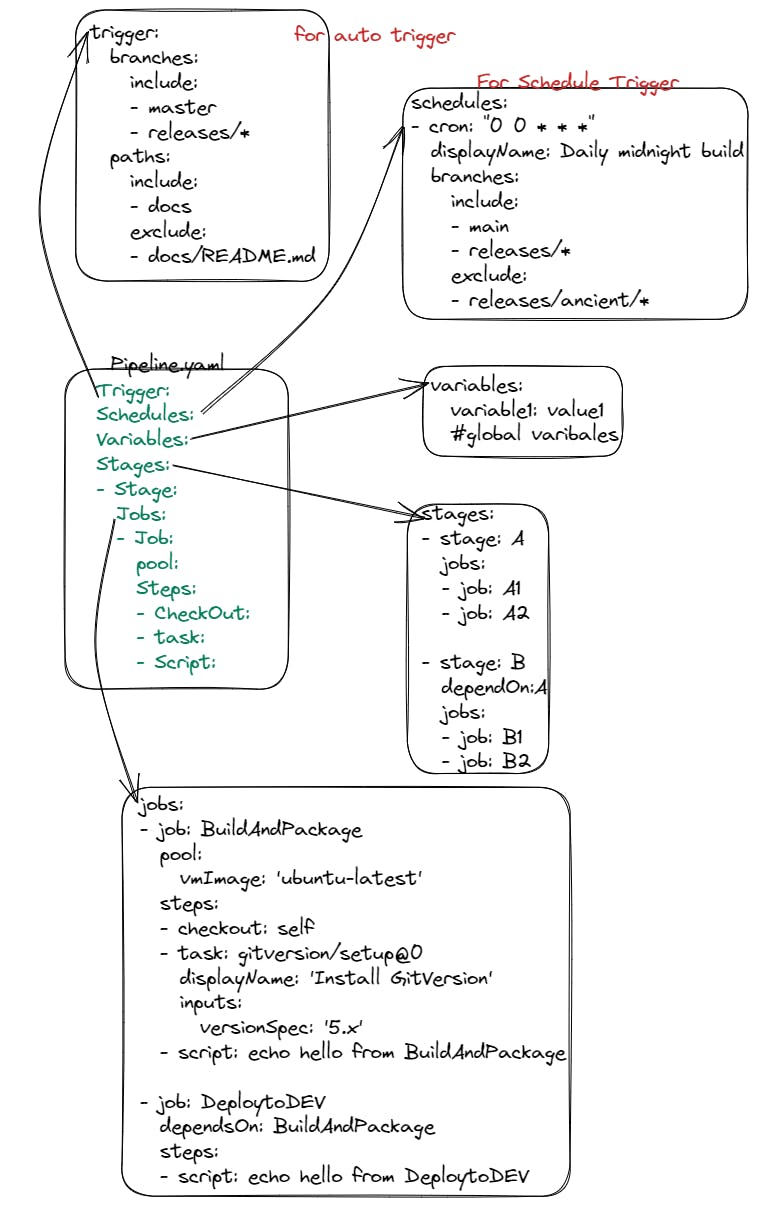
Azure Pipelines terms
Agent
When your build or deployment runs, the system begins one or more jobs. An agent is a computing infrastructure with installed agent software that runs one job at a time. For example, your job could run on a Microsoft-hosted Ubuntu agent.
For more in-depth information about the different types of agents and how to use them, see Azure Pipelines Agents.
Approvals
Approvals define a set of validations required before a deployment runs. Manual approval is a common check performed to control deployments to production environments. When checks are configured on an environment, pipelines will stop before starting a stage that deploys to the environment until all the checks are completed successfully.
Artifact
An artifact is a collection of files or packages published by a run. Artifacts are made available to subsequent tasks, such as distribution or deployment. For more information, see Artifacts in Azure Pipelines.
Continuous delivery
Continuous delivery (CD) is a process by which code is built, tested, and deployed to one or more test and production stages. Deploying and testing in multiple stages helps drive quality. Continuous integration systems produce deployable artifacts, which include infrastructure and apps. Automated release pipelines consume these artifacts to release new versions and fixes to existing systems. Monitoring and alerting systems run constantly to drive visibility into the entire CD process. This process ensures that errors are caught often and early.
Continuous integration
Continuous integration (CI) is the practice used by development teams to simplify the testing and building of code. CI helps to catch bugs or problems early in the development cycle, which makes them easier and faster to fix. Automated tests and builds are run as part of the CI process. The process can run on a set schedule, whenever code is pushed, or both. Items known as artifacts are produced from CI systems. They're used by the continuous delivery release pipelines to drive automatic deployments.
Deployment
For Classic pipelines, deployment is the action of running the tasks for one stage, which can include running automated tests, deploying build artifacts, and any other actions specified for that stage.
For YAML pipelines, a deployment typically refers to a deployment job. A deployment job is a collection of steps that are run sequentially against an environment. You can use strategies like run once, rolling, and canary for deployment jobs.
Deployment group
A deployment group is a set of deployment target machines that have agents installed. A deployment group is just another grouping of agents, like an agent pool. You can set the deployment targets in a pipeline for a job using a deployment group. Learn more about provisioning agents for deployment groups.
Environment
An environment is a collection of resources, where you deploy your application. It can contain one or more virtual machines, containers, web apps, or any service that's used to host the application being developed. A pipeline might deploy the app to one or more environments after the build is completed and tests are run.
Job
A stage contains one or more jobs. Each job runs on an agent. A job represents an execution boundary of a set of steps. All of the steps run together on the same agent. Jobs are most useful when you want to run a series of steps in different environments. For example, you might want to build two configurations - x86 and x64. In this case, you have one stage and two jobs. One job would be for x86 and the other job would be for x64.
Pipeline
A pipeline defines the continuous integration and deployment process for your app. It's made up of one or more stages. It can be thought of as a workflow that defines how your test, build, and deployment steps are run.
For Classic pipelines, a pipeline can also be referred to as a definition.
Release
For Classic pipelines, a release is a versioned set of artifacts specified in a pipeline. The release includes a snapshot of all the information required to carry out all the tasks and actions in the release pipeline, such as stages, tasks, policies such as triggers and approvers, and deployment options. You can create a release manually, with a deployment trigger, or with the REST API.
For YAML pipelines, the build and release stages are in one, multi-stage pipeline.
Run
A run represents one execution of a pipeline. It collects the logs associated with running the steps and the results of running tests. During a run, Azure Pipelines will first process the pipeline and then send the run to one or more agents. Each agent will run jobs. Learn more about the pipeline run sequence.
For Classic pipelines, a build represents one execution of a pipeline.
Script
A script runs code as a step in your pipeline using command line, PowerShell, or Bash. You can write cross-platform scripts for macOS, Linux, and Windows. Unlike a task, a script is custom code that is specific to your pipeline.
Stage
A stage is a logical boundary in the pipeline. It can be used to mark separation of concerns (for example, Build, QA, and production). Each stage contains one or more jobs. When you define multiple stages in a pipeline, by default, they run one after the other. You can specify the conditions for when a stage runs. When you are thinking about whether you need a stage, ask yourself:
Do separate groups manage different parts of this pipeline? For example, you could have a test manager that manages the jobs that relate to testing and a different manager that manages jobs related to production deployment. In this case, it makes sense to have separate stages for testing and production.
Is there a set of approvals that are connected to a specific job or set of jobs? If so, you can use stages to break your jobs into logical groups that require approvals.
Are there jobs that need to run for a long time? If you have part of your pipeline that will have an extended run time, it makes sense to divide them into their own stage.
Step
A step is the smallest building block of a pipeline. For example, a pipeline might consist of build and test steps. A step can either be a script or a task. A task is simply a pre-created script offered as a convenience to you. To view the available tasks, see the Build and release tasks reference. For information on creating custom tasks, see Create a custom task.
Task
A task is the building block for defining automation in a pipeline. A task is packaged script or procedure that has been abstracted with a set of inputs.
Trigger
A trigger is something that's set up to tell the pipeline when to run. You can configure a pipeline to run upon a push to a repository, at scheduled times, or upon the completion of another build. All of these actions are known as triggers. For more information, see build triggers and release triggers.
Library
The Library includes secure files and variable groups. Secure files are a way to store files and share them across pipelines. You may need to save a file at the DevOps level and then use it during build or deployment. In that case, you can save the file within Library and use it when you need it. Variable groups store values and secrets that you might want to be passed into a YAML pipeline or made available across multiple pipelines.
Check this article for more details